本文主要目的是生成自包含的(self-contained)句子,使其没有指代和依赖于对话历史中的其他句,进而促进回复选择和生成任务。
paper: https://drive.google.com/open?id=1B4ts8jU3Xx_TJuS9rgcBP3E17DFbegK6
Introduction
本文研究的是对话重写任务,给定一段对话和回复,目的是将多轮的对话上下文改写为单句话,如下图所示:

本文主要目的是生成自包含的(self-contained)句子,使其没有指代和依赖于对话历史中的其他句,主要有三个作用:
- 有助于检索式chatbot的检索过程
- 有助于可解释和可控对话建模
- 重写后的结果可以让多轮问答变成单轮问答任务,单论问答的技术更加成熟。
Model
本文提出了一种上下文重写网络(context rewriting network),融合对话上下文的关键信息与对话最后一句来改写,进而提高回复的准确率。模型结构如下:

模型的核心是Seq2Seq+CopyNet,编码器和解码器都是双向GRU。在解码端的每一时间步,CRN融合了context c, last utterance q以及上一步隐层状态作为输入:
$$
z_{t}=W_{f}^{T}\left[s_{t} ; \sum_{i=1}^{n q} \alpha_{q_{i}} h_{q_{i}} ; \sum_{i=1}^{n c} \alpha_{c_{i}} h_{c_{i}}\right]+b
$$
其中$\alpha_{q}, \alpha_{c}$都是注意力权重。
$$
\begin{aligned} \alpha_{i} &=\frac{\exp \left(e_{i}\right)}{\sum_{j=1}^{n} \exp \left(e_{j}\right)} \\ & e_{i}=h_{i} W_{a} s_{t} \end{aligned}
$$
模型最后使用CopyNet来预测目标词:
$$
\begin{aligned} p\left(y_{t} | s_{t}, H_{Q}, H_{C}\right) &=p_{p r}\left(y_{t} | z_{t}\right) \cdot p_{m}\left(p r | z_{t}\right) \\ &+p_{c o}\left(y_{t} | z_{t}\right) \cdot p_{m}\left(c o | z_{t}\right) \end{aligned} \\
p_{m}\left(p r | z_{t}\right)=\frac{e^{\psi_{p r}\left(y_{t}, H_{Q}, H_{C}\right)}}{e^{\psi_{p r}\left(y_{t}, H_{Q}, H_{C}\right)}+e^{\psi_{c o}\left(y_{t}, H_{Q}, H_{C}\right)}}
$$
Pre-training with Pseudo Data
因为数据集中并没有改写句的标注,因此作者从对话历史中抽取关键词来构造模拟数据。具体来说,作者使用了PMI来抽取一段文本中的关键词,核心是下式:
$$
\operatorname{PMI}\left(w_{c}, w_{r}\right)=-\log \frac{p_{c}\left(w_{c}\right)}{p\left(w_{c} | w_{r}\right)}
$$
$w_{c}$ 是context word,$w_{r}$ 是response word。为了选择对回复来说最重要的词,作者也计算了$PMI(w_{c}, w_{q})$ ($w_{q}$是last utterance的词),最终的PMI分数为:
$$
\operatorname{norm}\left(\operatorname{PMI}\left(w_{c}, q\right)\right)+\operatorname{norm}\left(\operatorname{PMI}\left(w_{c}, r\right)\right) \\
\operatorname{PMI}\left(w_{c}, q\right)=\sum_{w_{q} \in q} \operatorname{PMI}\left(w_{c}, w_{q}\right)
$$
然后选择PMI分数最高的20%词插入last utterance,这里通过语言模型来选择插入位置,保留前3个改写后的句子。接着使用对话生成和回复选择模型来从总挑选最佳改写句作为标注,具体来说,通过以下两个损失函数的值来选择: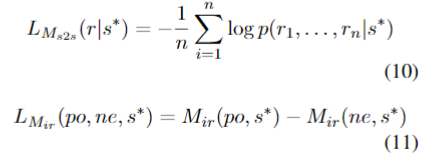
Fine-Tuning with Reinforcement Learning
上述生成模拟数据难免包含错误,作者又使用了RL来优化CRN的性能。作者首先在模拟数据上预训练CRN模型,然后使用该模型产生候选改写句$q_{r}$,在生成过程中应用policy gradient算法:
$$
\nabla_{\theta} J(\theta)=E\left[R \cdot \nabla \log \left(P\left(y_{t} | x\right)\right)\right] \\
L_{c o m}=L_{r l}^{*}+\lambda L_{M L E}
$$
论文使用下游任务来给定奖励:
回复生成:
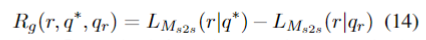
回复选择:
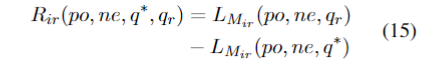
Experiments
作者使用了四种评价指标来评估模型性能:改写质量,回复生成,回复选择,检索式chatbot。
Rewriting Quality Evaluation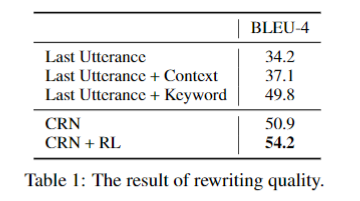
Multi-turn Response Generation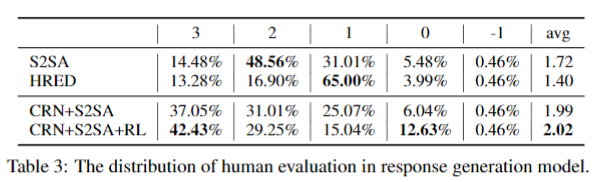
Multi-turn Response Selection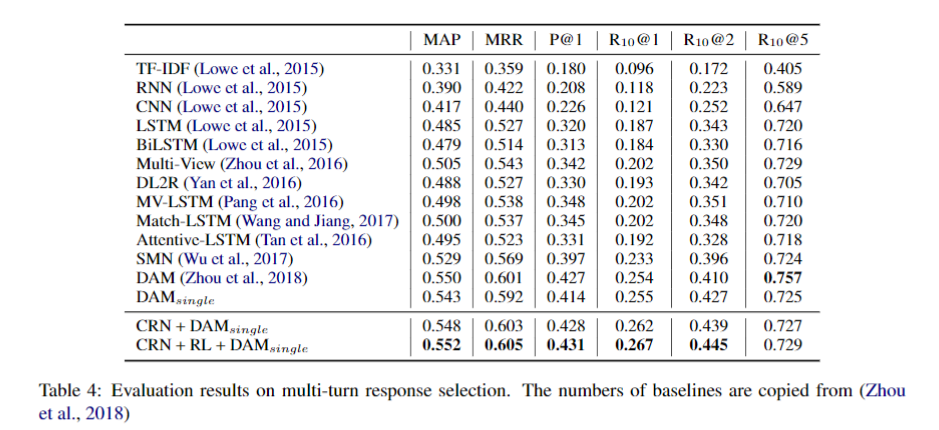
End-to-End Multi-turn Response Selection
这个任务主要是评估改写句对检索的影响,因为大部分的工作集中于从检索后的候选集做匹配,而本文更加关注如何来得到这个候选集。当然,评价指标仍然是匹配结果,因为检索结果不好衡量。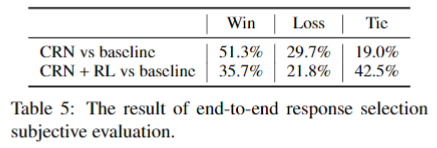
Case Study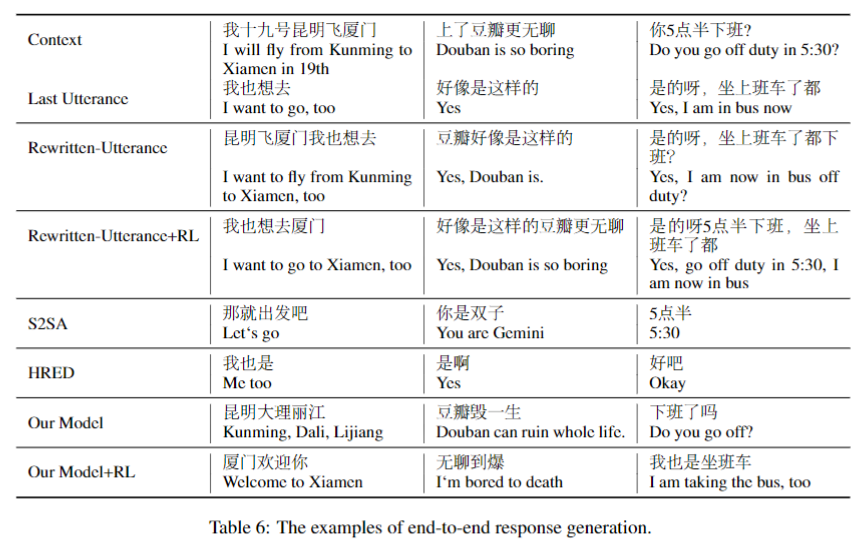
Conclusion
本文研究了开放域对话建模问题,提出了一种无监督对话重写方法,促进了下游对话生成和选择任务。